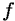 , na které by musel běžet referenční
procesor, tak abychom dosáhli stejného času pro výpočet jako u testovaného procesoru:
, na které by musel běžet referenční
procesor, tak abychom dosáhli stejného času pro výpočet jako u testovaného procesoru:
V rámci své vědecké práce se zabýváme numerickými výpočty v oblasti modelování optiky tenkých vrstev. Před deseti lety kvůli nedostatku dostatečně výkonného počítače na našem pracovišti jsem tyto výpočty prováděl na heterogenním clusteru, který obsahoval tehdejší superpočítač Masarykovy univerzity (čtyřprocesorový 64 bitový systém od SGI) a několik unixových výpočetních stanic od různých výrobců (SUN, SGI, DEC atd.), které jsem posbíral po celé univerzitě. Protože výkon tohoto clusteru mi záhy přestal stačiti a velká část kolegů v té době začínala používat PC s některou distribucí LINUXu jako svůj stolní počítač, začal jsem tyto počítače do clusteru přidávat. Díky rostoucímu výkonu stolních počítačů jsme nakonec naše výpočty přenesly na cluster, který je dnes tvořen pouze z PC s operačním systémem LINUX. Abychom dosáhli co největšího výkonu a také poměru cena/výkon, začali jsme procesory testovat. Aby testy byly pro nás objektivní, používali jsme pro testování různé části svých modelů. Protože naše testy jsou často v rozporu se všeobecně používanými benchmarkovými programy, začal jsem zkoumat příčinu tohoto faktu. Výsledkem je, že jsme vyvinuli pro naši potřebu program bm2008 pro testování rychlosti procesorů. S výsledky těchto testů bychom rádi seznámili širší veřejnost.
V současné době používáme následující tři testovací programy:
První s názvem rrt je nejstarší, který používáme pro testování procesorů. Kód reprezentuje dvojný integrál jistých
komplexních funkcí. Tato část reprezentuje test, který procesor zatíží výpočty s plovoucí desetinou čárkou.
Pro úplnost, RRT je zkratka poruchové teorie v optice rozptylu světla a koho by to zajímalo, uvádím referenci na článek týkající se RRT.
Reference:
Franta D., Ohlídal I., Nečas D., Influence of cross-correlation effects on the optical quantities of rough films,
Optics Express 16 (2008) 7789–7803.
Tato část počítá dielektrickou funkci diamantu podobných vrstev (DLC) za pomocí námi vyvinutého tzv. PDOS modelu (viz. reference).
V tomto kódu opět převažují výpočty s plovoucí desetinou čárkou, ale ve výsledku se kód chová jinak než rrt.
Reference:
Franta D., Nečas D., Zajíčková L., Models of dielectric response in disordered solids,
Optics Express 15 (2007) 16230–16244.
I když v našich modelech, které požíváme v praxi převažují výpočty s plovoucí desetinou čárkou, chtěli jsme doplnit náš test o část,
která by otestovala procesor v celočíselné aritmetice. Proto jsme doplnili náš program o test, který je založený na Levenshteinovým
algoritmu počítající vzdálenost mezi textovými řetězci.
Reference:
Levenshtein distance, Wikipedia .
Absolutní rychlost procesorů je definována jako frekvence , na které by musel běžet referenční
procesor, tak abychom dosáhli stejného času pro výpočet jako u testovaného procesoru:
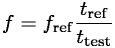
kde 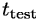 ,
, 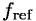 a
a 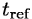 je čas, který jsme dosáhli
při výpočtu na testovacím procesoru, frekvence referenčního procesoru a čas, který jsme dosáhli na referenčním procesoru.
Výsledné časy záleží též na optimalizaci a verzi kompilátoru. Jako referenční procesor jsme zvolili procesor Pentium 150.
Tedy, má-li procesor rate 5000 MHz, znamená to, že tento procesor spočítá úlohu tak, jak by ji spočítal procesor Pentium taktovaný na 5 GHz.
je čas, který jsme dosáhli
při výpočtu na testovacím procesoru, frekvence referenčního procesoru a čas, který jsme dosáhli na referenčním procesoru.
Výsledné časy záleží též na optimalizaci a verzi kompilátoru. Jako referenční procesor jsme zvolili procesor Pentium 150.
Tedy, má-li procesor rate 5000 MHz, znamená to, že tento procesor spočítá úlohu tak, jak by ji spočítal procesor Pentium taktovaný na 5 GHz.
Efektivita procesorů je definována jako poměr absolutní rychlosti a skutečné frekvence jádra testovaného procesoru:
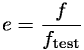
Tedy procesor Pentium má efektivitu 1. Procesor, který například dosahuje efektivitu 2, spočítá úlohu dvakrát rychleji než by ji spočítal procesor Pentium taktováný na stejné frekvenci.
Pro testování procesorů je nutné procesory rodělit nejen podle výrobce, ale i podle typu jádra. Jelikož existuje značné množství typů procesorových jader a některá jádra se z hlediska testovaného výkonu příliš neliší, tak jsme zavedli následující klasifikaci:
Seznam procesorů, které byly testovány, jsou uvedeny v následující tabulce.
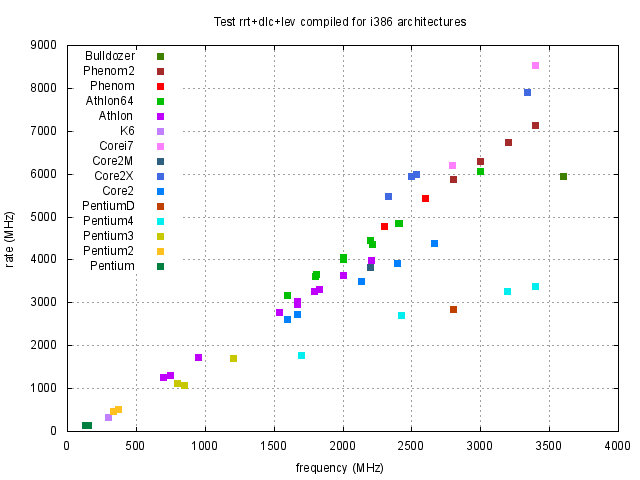
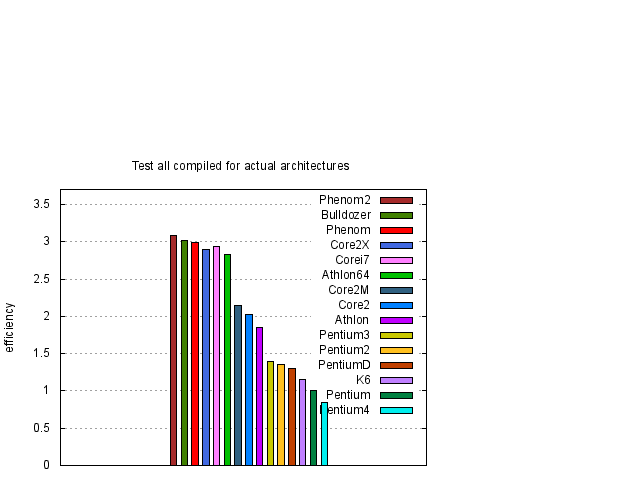
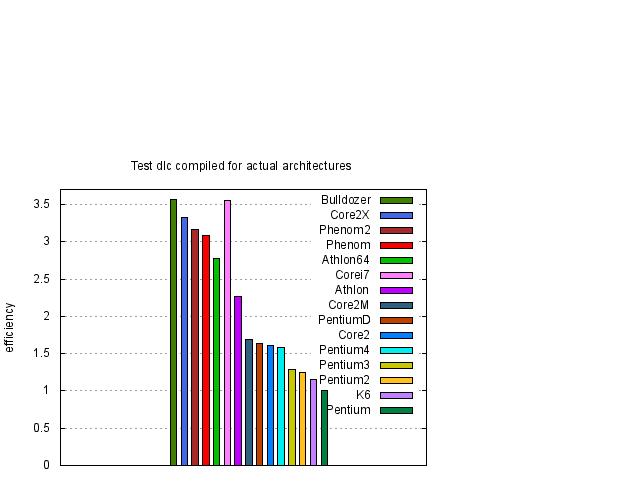
Nejprve uvedeme výsledky souhrnného testu, který je složen ze všech tří jednotlivých testů, tj. rrt, dlc a lev. Jde tedy o jakési jejich zprůměrování, protože délka jednotlivých testů je volena tak, aby byla přibližně stejná. Výsledky jsou uvedeny v grafické formě na obrázku 1.
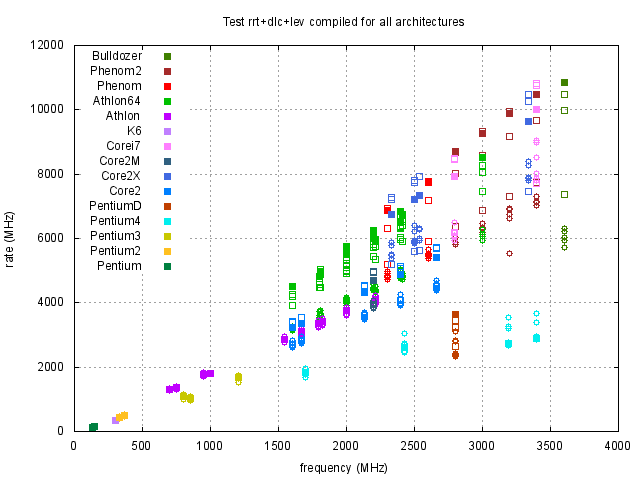
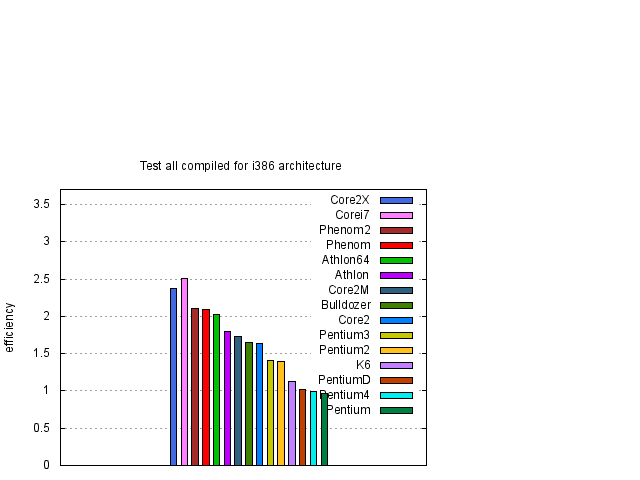
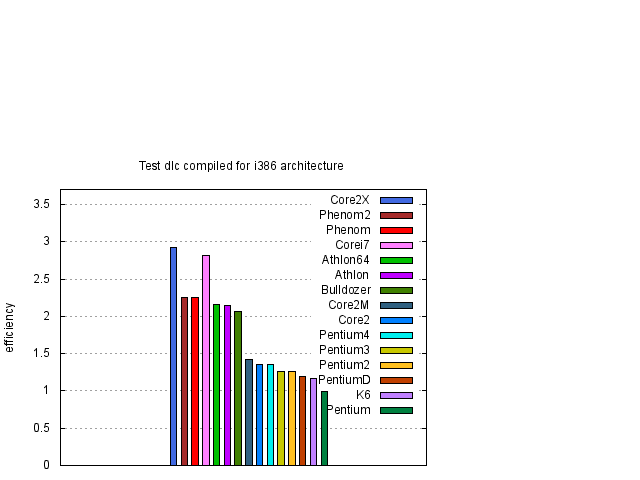
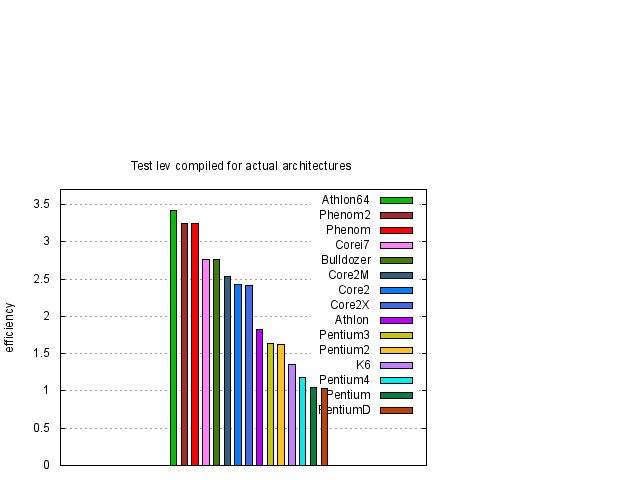
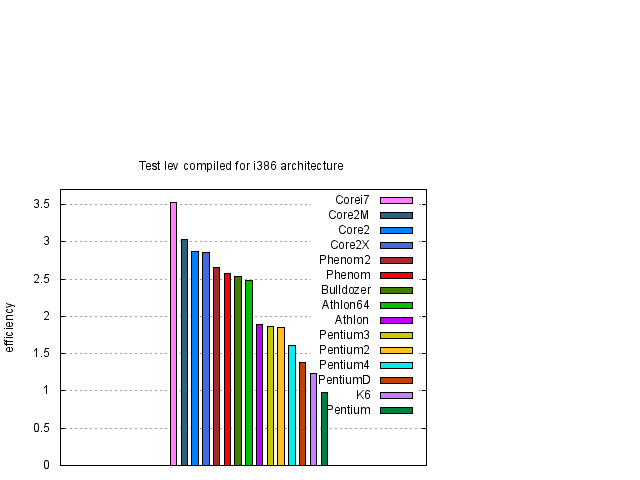
Z obrázku 1 je vidět, že největší, nebo téměř největší, rychlost procesorů v závislosti na typu kódu dostaneme pro nativní kódy odpovídající danému procesoru. Pouze pro procesory Pentium 4 taktované na vyšších frekvencích toto tvrzení neplatí. Abychom výsledky zpřehlednili, na obrázcích 2 a 3 vybereme výsledky, kde jsou uvedeny pouze data nativního a i386 kódu.
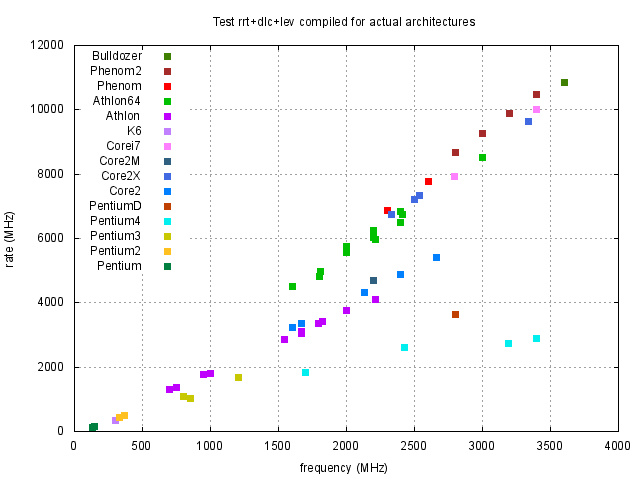
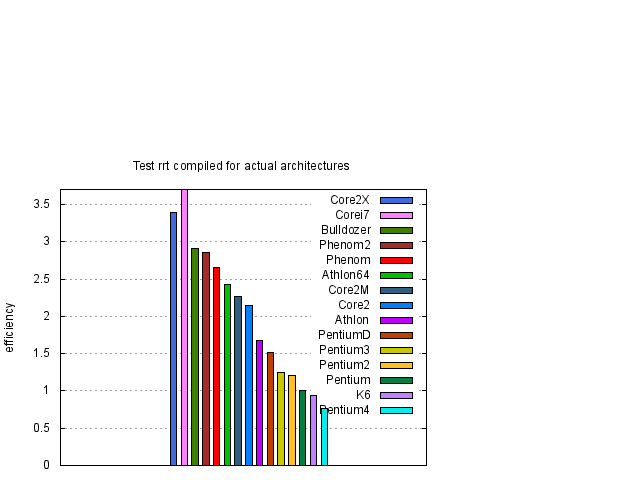
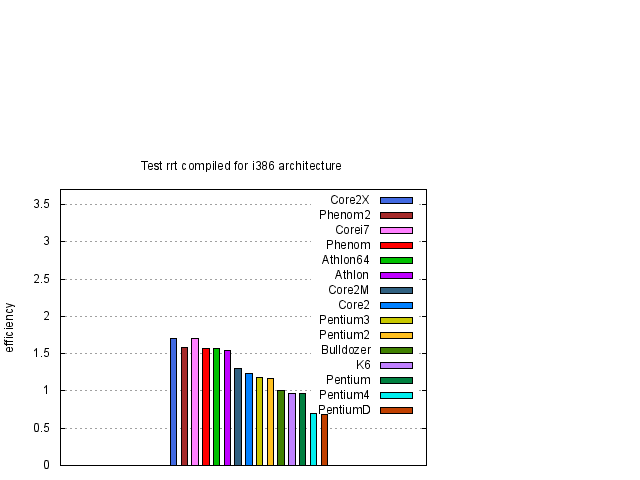
Z obrázků 1, 2 a 3 je vidět, že rychlost závisí na typu procesoru přibližně lineárně na frekvenci procesoru. Pro posouzení kvality návrhu procesoru je účelné si výsledky zobrazit za pomocí efektivity procesoru, kterou jsme definovali dříve. Proto jsme stejné výsledky z obrázků 1, 2 a 3 zobrazili za pomocí efektivity na obrázcích 4, 5 a 6.
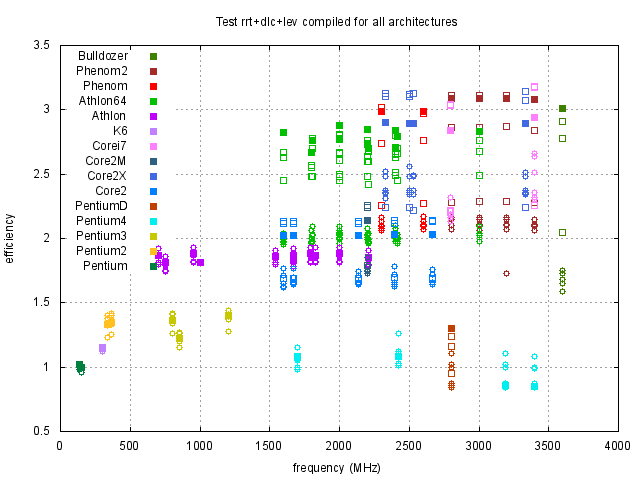
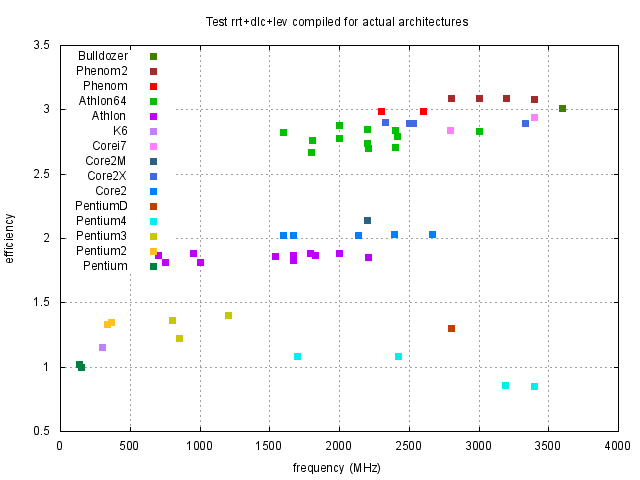
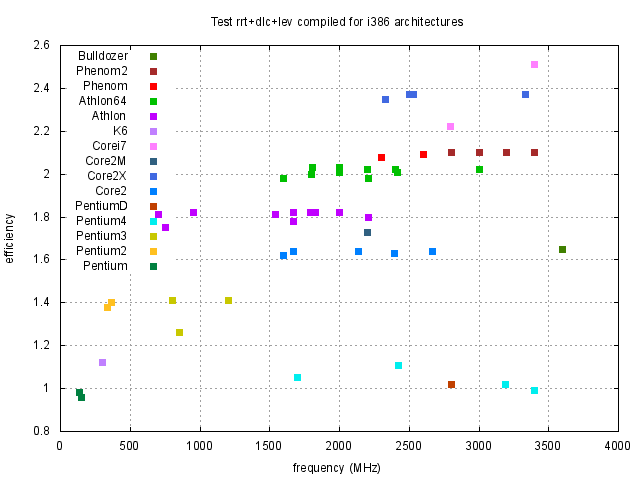
Z předchozího vyplývá, že nemusíme testy dělat pro všechny procesory, ale bude stačit, když si z každého typu procesoru vybereme jeden reprezentativní (v našem případě ten s největší efektivitou) a skutečný výkon potom vypočteme tak, že efektivitu procesoru vynásobíme frekvencí jádra.
Abychom se na testované procesory podívali hlouběji, provedeme jednotlivé testy.
K tomuto srovnání jsme vybrali nejrychlejší procesory od obou konkurenčních firem, které vystupují v našem testu:
Intel Core i7 CPU 860 @ 2.80 GHz
AMD Phenom II X4 965 Processor @ 3.4 GHz
AMD Phenom II X6 1090T Processor @ 3.2 GHz
Procesor Core i7 má 1/1/4/5 turbo módy. To znamená že je-li zpracováván jeden proces a teplota jádra je nízká, tak se frekvence jádra zvýší na frekvenci 2.8 + 5 * 0.133 = 3.46 GHz. Při větším zatížení jsou-li zpracovávány dva procesy, frekvence je 2.8 + 4 * 0.133 = 3.33 GHz a při třech a více procesech je frekvence 2.8 + 0.133 = 2.93 GHz. Navíc procesor Core i7 má Hyper-Threading technologii, tedy dvojnásobný počet vituálních jader, který přidá přibližně 20% výkonu, zpracovává-li procesor osm a více úloh. Dále z obrázku 1 je vidět, že pro procesory Core 2 a i7 se nejlepších výsledků dosahuje při použití optimalizace pro Phenomy (amdfam10). Přičemž největší rozdíl je v testu lev, viz následující tabulka efektivity procesoru i7:
| test / kód | core2 | amdfam10 |
|---|---|---|
| rrt | 3.18 | 3.23 |
| dlc | 2.63 | 2.64 |
| lev | 2.76 | 3.28 |
Procesor Phenom II X6 má technologii Turbo Core (ekvivalent Turbo Boost technologie), takže při zatížení jedním až třemi procesy je jádro taktováno na frekvenci 3.6 GHz, zatímco při zatížení procesor sníží frekvenci na nominální hodnotu 3.2 GHz.
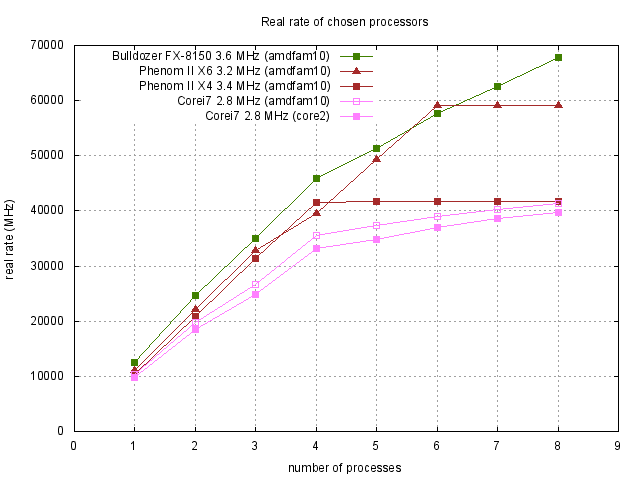
Reálné výkony procesorů potom změříme tak, že testy spustíme paralelně v několika vláknech (v našem případě v jednom až osmi vláknech) a sledujeme dosažených časů jednotlivých vláken. U systému, který rovnoměrně rozdělí úlohy mezi jednotlivá jádra, které při jakýmkoliv zatížení běží na konstantní frekvenci, tj. Phenom II X4, pozorujeme lineární nárůst výkonu s počtem vláken, až do celkového počtu jader v procesoru. Po překročení počtu vláken nad počtem jader procesoru se výkon nadále nezvyšuje (viz. výsledky na obrázku 11 pro AMD Phenom II X4 procesor). U procesoru využívající Turbo Boost a Hyper-Threading technologii je situace jiná. Při spuštění testu na jednom vláknu procesor Core i7 běží na maximální frekvenci 3.46 GHz a jeho výkon je ve srovnání s Phenom II procesorem téměř totožný. Při běhu testu ve dvou až čtyřech vláknech se sníží frekvence jádra na 3.33 respektive 2.93 GHz, které se projeví v nižším výkonu ve srovnání s Phenom II procesorem. Zatížíme-li ale procesor testy v pěti až osmi vlákny, situace se díky technologii Hyper-Threading začne srovnávat, přičemž při osmi vláknech procesor Core i7 znovu dosahuje rychlosti procesoru Phenom II X4 (viz. obrázek 11). U procesoru Phenom II X6 se projeví fakt, že má 6 fyzických jader, proto i když je taktovaný na nižší frekvenci než je procesor Phenom II X4, tak při 6 vláknech dosáhne nejvyššího výkonu v našem testu (viz. obrázek 11).
Za pomocí předešlých testů je možné odhadnout realné maximální výkony procesorů, které jsme zatím netestovali, ale jsou v prodeji. V následující tabulce uvádíme tento výkon pro vybrané procesory:
| procesor | max rate [GHz] | cena [Kč] | max rate/cena |
|---|---|---|---|
| Intel Core i7 CPU 980X @ 3.33 GHz | 73900 | 26399 | 2.80 |
| AMD Phenom II X6 1090T Processor @ 3.2 GHz | 58700 | 7787 | 7.54 |
| AMD Phenom II X6 1055T Processor @ 2.8 GHz | 51400 | 4990 | 10.30 |
| Intel Core i7 CPU 975 @ 3.33 GHz | 49200 | 25828 | 1.90 |
| Intel Core i7 CPU 870 @ 2.93 GHz | 43300 | 13188 | 3.28 |
| AMD Phenom II X4 965 Processor @ 3.4 GHz | 41700 | 4490 | 9.29 |
| Intel Core i7 CPU 860 @ 2.80 GHz | 41400 | 7319 | 5.65 |
| AMD Phenom II X4 925 Processor @ 2.8 GHz | 34400 | 3683 | 9.34 |
Závěry uvedené v tomto odstavci jsou aplikovatelné pro uživatele, kteří počítače používají na numerické výpočty a sami si svůj kód kompilují. Předem upozorňuji, že závěry zde uvedené není možné zevšeobecňovat. Například běžní uživatelé Windows, kteří v počítači používají jen již předem vytvořený software, většinou nevyužijí v počítači veškeré možnosti svých procesorů. Například uživatelé 32 bitové verze Windows XP, kteří vlastní některý z 64 bitových procesorů, ani tento procesor do 64 bitového kódu nepřepnou a tím většinou ztratí podstatnou část výkonu svého počítače. Zajisté kapitolu samu pro sebe budou tvořit uživatelé her. Čistě obecně se dá říci, že bude záležet na tom jaký kód daný program používá a na jakém kompilátoru, respektive s jakými optimalizacemi, je kód kompilován. Nedá se tedy hodnotit úroveň procesorů podle jednoho kódu a nebo podle kódů, které jsou optimalizované pro jeden typ procesorů. Z mých zkušeností většina programů dostupných pro PC jsou kompilované ve 32 bitovém módu optimalizované pro procesory Intel a využívající jen celočíselnou aritmetiku. Takže ve skutečnosti pro běžného uživatele je asi relevantní test lev kompilovaný pro i386 (viz. obrázek 9). Navíc se jistě musí zhodnotit i faktor ceny procesoru a frekvence s kterou jsme schopni daný procesor koupit. Navíc jak bylo vidět naše testy nejsou závislé na velikosti L2 vyrovnávací paměti a jistě existují numerické aplikace, které budou na velikosti této paměti závislé. Proto žádám, aby tyto skutečnosti byly vzaty v úvahu, a aby mě skalní příznivci jedné a nebo druhé firmy neobviňovali ze zkreslování výsledků. Každopádně, každý má možnost si testy zopakovat.
Nejprve si stáhněte testovací program a uložte na USB flashdisk.
Na CD si vypalte nějakou live distribuci Linuxu, např. live openSuSE .
Nastartujte Linux a přepněte se na konzolu, t.j. textový terminál (Ctr+Alt+F1). Přihlaste se jako root (heslo systém nevyžaduje).
Nemusíte mít obavu, váš harddisk bude v bezpečí, nebude vůbec připojený, takže vaše Windows budou v bezpečí.
Místo pevného disku se vám vytvořil v live systému virtuální ramdisk.
Vytvořte adresář disk pomocí příkazu:
> mkdir disk
Pak do tohoto adresáře přípojíme USB flashdisk, která se nám většinou jeví v počítači jako zařízení /dev/sdb:
> mount -t vfat /dev/sdb /root/disk
Toto platí když, počítač obsahuje jenom jeden harddisk (/dev/sda), který není avšak připojený. Máme-li v počítači více disků,
nebo jiné čtecí zařízení, musíme v předcházejícím příkazu zvolit ten poslední. Jaké disky máme v počítači zjistíme pomocí:
> ls /dev/sd*
Máme-li disk připojený, změníme aktuální adresář:
> cd disk
Nyní se nacházíme v adresáři /root/disk, který obsahuje soubor >bm2008.tgz s archivem, který jsme si tam již dříve uložili.
Archív rozbalíme pomocí příkazu:
> tar xzf bm2008.tgz
Příkaz vytvořil adresář bm2008, do kterého přejdeme:
> cd bm2008
V adresáři bm2008 nalezneme zdrojový kód bm2008.cxx, soubor Makefile, který používá příkaz make a již překompilované
spustitelné programy bm2008-k8, bm2008-core2 atd. Zdatní uživatelé mohou využít zdrojový kód a Makefile ke
zkompilování vlastních binárek a otestování své verze kompilátoru (dosažené výsledky závisí na kompilátoru a na jeho verzi).
Začátečníci nemusí nic kompilovat a využijí k testu již zkompilované programy. Jednotlivé testy se spustí pomocí příkazu:
> bm2008-ARCH benchmark ...
kde ARCH značí architekturu pro kterou je program optimalizován a benchmark je typ testu který se spustí. V tuto chvíli
jsou k dispozici tři testy, t.j. rrt, dlc a lev. Význam těchto zkratek je vysvětlen výše v samostatných kapitolách.
Architektury, pro které jsme kód zkompilovali jsou následující:
Takže chceme-li například spustit test rrt na 64 bitovém počítači a chceme-li aby kód byl optimalizován pro Athlon 64, tak zadáme:
> ./bm2008-k8 rrt
s následujícím výstupem:
benchmark : bm2008 rrt compilator : g++ (SUSE Linux) 4.3.1 20080507 (prerelease) [gcc-4_3-branch revision 135036] compiled as : g++ -O2 -ffast-math -static -m64 -march=k8 -DCOMPH="comp-k8.h" -o bm2008-k8 bm2008.cxx cpu family : 15 model : 67 model name : AMD Athlon(tm) 64 X2 Dual Core Processor 6000+ stepping : 3 cache size : 1024 KB cpu cores : 2 cpu MHz : 3000.000 MHz user time : 0m37.330s rate : 7102 rate/cpu MHz : 2.37Chceme-li spustit všechny tři testy v 32 bitovém kódu kompatibilním s procesorem Intel 80386 a navíc chceme, aby se výstup kromě na terminál uložil do souboru out, tak zadáme:
benchmark : bm2008 rrt dlc lev compilator : g++ (SUSE Linux) 4.3.1 20080507 (prerelease) [gcc-4_3-branch revision 135036] compiled as : g++ -O2 -ffast-math -static -m32 -march=i386 -DCOMPH="comp-i386.h" -o bm2008-i386 bm2008.cxx cpu family : 15 model : 67 model name : AMD Athlon(tm) 64 X2 Dual Core Processor 6000+ stepping : 3 cache size : 1024 KB cpu cores : 2 cpu MHz : 3000.000 MHz user time : 2m22.770s rate : 6069 rate/cpu MHz : 2.02Chcete-li vyzkoušet jak se procesor byde chovat, když spustíte test například šestkrát, použijte přepínač -n následujícím způsobem:
bm2008 -n6 rrt dlc lev compilator : g++ (SUSE Linux) 4.3.2 [gcc-4_3-branch revision 141291] compiled as : g++ -O2 -ffast-math -static -m64 -march=amdfam10 -DCOMPH="comp-amdfam10.h" -o bm2008-amdfam10 bm2008.cxx cpu family : 16 model : 4 model name : AMD Phenom(tm) II X4 965 Processor stepping : 2 cache size : 512 KB cpu cores : 4 real time 1 : 2m2.910s real time 2 : 2m3.490s real time 3 : 2m4.240s real time 4 : 2m4.750s real time 5 : 2m6.260s real time 6 : 2m7.050s mean time : 2m4.783s real rate : 41663Všimněte si, že operační systém rozdělil šest výpočtů mezi čtyři jádra u AMD procesoru přibližně stejně. Když stejný výpočet provedeme na Core i7, která má HT technologii, tak se výpočty nerozvrhnou mezi jádra stejnoměrně a budou se počítat s velmi rozlišnými časy: > ./bm2008-amdfam10 -n6 rrt dlc lev | tee out-n6-all-amdfam10
benchmark : bm2008 -n6 rrt dlc lev compilator : g++ (SUSE Linux) 4.3.2 [gcc-4_3-branch revision 141291] compiled as : g++ -O2 -ffast-math -static -m64 -march=amdfam10 -DCOMPH="comp-amdfam10.h" -o bm2008-amdfam10 bm2008.cxx cpu family : 6 model : 30 model name : Intel(R) Core(TM) i7 CPU 860 @ 2.80GHz stepping : 5 cache size : 8192 KB cpu cores : 4 real time 1 : 1m55.830s real time 2 : 2m3.660s real time 3 : 2m12.330s real time 4 : 2m12.850s real time 5 : 2m17.480s real time 6 : 2m38.040s mean time : 2m13.365s real rate : 38982Jestli si myslíte, že váš procesor chybí ve výsledcích uvedených na této stránce spusťte následující skript: